To the untrained eye, an HTML document is a jumble of text and funny punctuation. Let's unjumble this very short document by examining it under a microscope:
The text DOCTYPE is short for document type declaration. The declaration you see here tells the browser that this document follows the HTML5 standard. Older versions of HTML used a different declaration. Notice there's no explicit mention of HTML5. Who knows how this line will change when HTML6 comes along.
A document is composed of elements. There's a single root element from which all other content stems. The root element is opened with <html> and closed with </html>. Inside the root you see a head element. The head element contains metadata that describes the content of the file. In this example, the only metadata is the title of the page. The browser displays the title in the tab or window titlebar.
The Preview of this document is blank. This document happens to have no visible content. Visible content is placed in the body element, as you see in this more complete example:
Notice how body is nested inside of html but not inside of head. The body element contains two elements: a heading and a paragraph. The heading element is marked with an h1 tag, and the paragraph with a p tag.
The paragraph contains an image element. The img tag is a bit different than the other tags in this document. It contains two key-value pairs. These are called attributes. The src attribute holds the address of the image and the alt attribute provides a meaningful textual description of the image content. In Preview, the image appears broken because it hasn't been uploaded.
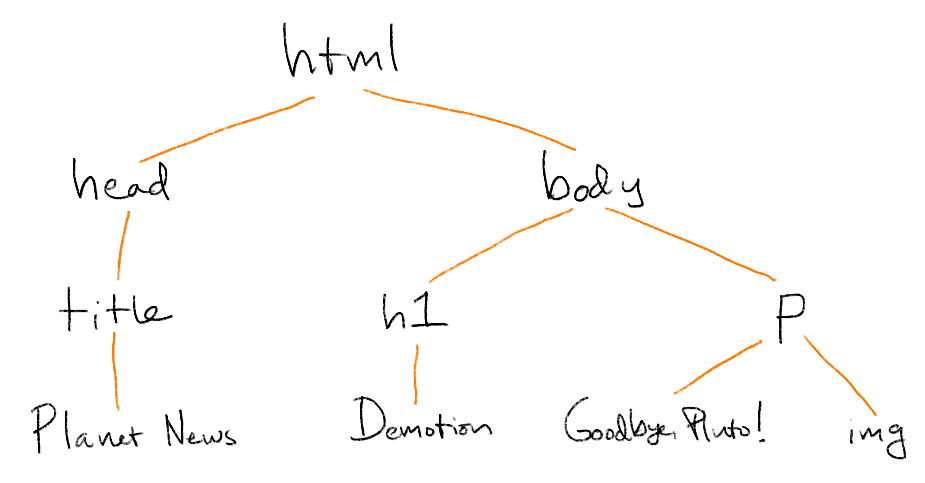
An HTML document is really a tree in disguise. The branching structure is flattened or serialized into a string of characters so that it can be saved in a file or sent across the internet. When the browser receives the HTML, it expands the text back into a tree that is called the Document Object Model (DOM). This document's tree looks something like this:
The tree metaphor suggests that the elements form a family. The root element has two children. The heading and paragraph elements are siblings. The parent of the image is the paragraph.
The HTML standard defines three different kinds of elements, all of which are shown in this tree. The first three leaf nodes are raw text elements, holding only text and no other elements. The remaining leaf node is the image element. It is a void element, which means it has no children and therefore doesn't need a closing tag. The remaining elements are normal elements, having both opening and closing tags with content sandwiched between.